Puoi avere il miglior modello di AI sul mercato e perderlo in una notte, senza aver fatto nulla di sbagliato
Nella notte italiana del 12 giugno il governo USA ha sospeso Fable 5, il modello di intelligenza artificiale più potente disponibile al pubblico, per tutti i cittadini non statunitensi. Non per un guasto. Per un decreto.
Immaginiamo, ed è un'ipotesi del tutto verosimile, un'azienda europea che ci aveva costruito sopra un processo critico. Si sarebbe trovata senza modello, senza preavviso, per una decisione presa in una stanza dove non era seduta.
Quando ho condiviso una prima riflessione su questo tema, un amico mi ha scritto una cosa che mi ha colpito: questa, in fondo, è la storia di Memori in generale, non solo di quest'ultimo episodio. Anticipare il futuro. Aveva ragione, e vale la pena spiegare perché.
Una storia fatta di anticipi
Memori nasce nel 2017 ad Altedo, in provincia di Bologna. Già allora parlavamo di agenti che simulavano persone e portavano a termine compiti, in un'epoca in cui la parola agente, riferita all'AI, non la usava quasi nessuno.
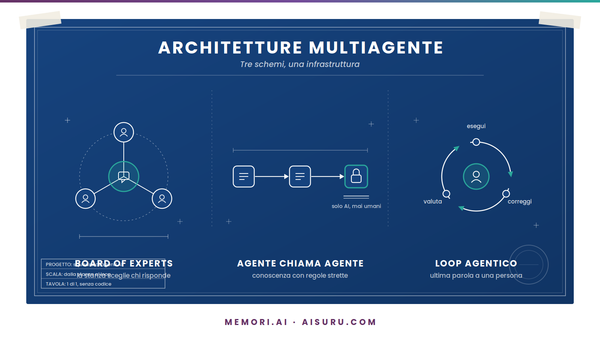
Da lì in poi abbiamo continuato a costruire guardando dove andava la tecnologia, non dove era già arrivata. Abbiamo dato agli agenti una memoria persistente, quando ancora i modelli dimenticavano tutto a ogni conversazione. Abbiamo creato la Board of Experts, una struttura in cui più agenti specializzati collaborano dentro un'unica interfaccia, prima che i sistemi multi agente diventassero un tema di moda. E abbiamo sviluppato i nostri connettori per portare gli agenti dentro i sistemi aziendali, connettori che oggi si sono evoluti in MCP, lo standard che il mercato ha adottato solo in seguito.
Ogni volta lo schema è stato lo stesso: vedere prima un bisogno, e costruirci sopra prima che diventasse evidente a tutti. Lo spegnimento di Fable, invece di spaventarmi, mi ha confermato la rotta. Perché il tema della dipendenza da un fornitore unico lo affrontiamo, nella pratica, da anni.
Il backup non esiste? La domanda è un'altra
In un commento qualcuno ha sollevato l'obiezione più onesta possibile: un backup equivalente a Fable oggi non esiste, è primo con distacco. Vero. Ma confondiamo due cose diverse.
Avere il modello più potente in assoluto è una gara che perderemo sempre, perché il primo della classe sarà di qualcun altro per qualche mese. Non poter essere staccati dalla presa è un'altra cosa, e quella partita possiamo vincerla. Anzi, abbiamo già in mano i pezzi.
La domanda quindi non è esiste un gemello identico di Fable. La domanda è cosa fai nelle ore in cui quel modello non c'è. E soprattutto, come Paese: possiamo permetterci che la risposta dipenda ogni volta da una firma a Washington?
Il software per l'indipendenza esiste già, ed è aperto
Negli ultimi due mesi sono usciti due modelli che un anno fa non avevamo. DeepSeek V4, 1.6 trilioni di parametri, licenza MIT, secondo modello aperto al mondo per capacità. E NVIDIA Nemotron 3 Ultra, 550 miliardi di parametri, uscito il 4 giugno con pesi, dati di training e ricette completamente aperti, costruito apposta per agenti che ragionano a lungo.
Nessuno dei due batte Fable sui task estremi. Entrambi, però, li scarichi e li fai girare a casa tua. Nessuno te li spegne da remoto.
Il pezzo che manca è il ferro. E qui smettiamo di parlare per slogan, perché i numeri si conoscono.
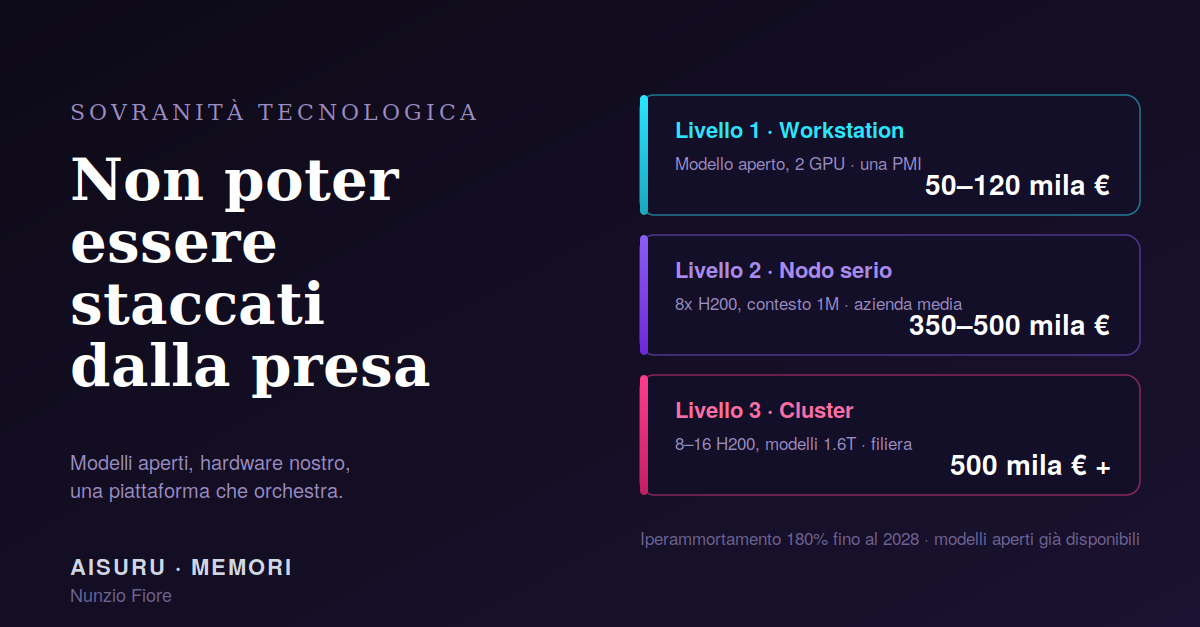
Tre livelli di macchina, con prezzi reali
Livello 1, la workstation di reparto. Un modello come Nemotron Super o DeepSeek V4-Flash, in versione quantizzata, gira su una macchina con un paio di GPU di fascia alta. Ordine di grandezza dai 50.000 ai 120.000 euro. È il box con cui una PMI mette in sicurezza i suoi casi d'uso interni, senza mandare un solo dato fuori.
Livello 2, il nodo singolo serio. Per servire DeepSeek V4-Flash a piena capacità, con contesto da un milione di token e più utenti insieme, servono circa 170 GB di memoria GPU, cioè due o quattro acceleratori H200. Un nodo da 8 H200 chiavi in mano costa oggi tra 350.000 e 500.000 euro. È la macchina di un'azienda media che fa sul serio.
Livello 3, il cluster. Per servire i modelli più grandi a 1.6 trilioni di parametri serve oltre un terabyte di memoria GPU, quindi otto o sedici H200 in un cluster con interconnessione veloce. Si parte da 500.000 euro e si sale. Non è roba da singola impresa. È esattamente il livello in cui ha senso un investimento di filiera, pubblico o consortile.
La leva fiscale che in Italia cambia il conto
L'iperammortamento al 180 percento, in vigore fino a settembre 2028, su un investimento da 150.000 euro in hardware e software 4.0 genera una base ammortizzabile maggiorata di 270.000 euro aggiuntivi. Tradotto in cassa, con IRES al 24 percento, sono circa 64.800 euro di minori imposte, distribuite lungo il periodo di ammortamento. Il costo netto dell'infrastruttura scende così sotto i 90.000 euro.
Non è uno sconto immediato, è un ammortamento maggiorato nel tempo. Ma cambia in modo sostanziale la convenienza del fare in casa.
Il piano, in quattro mosse
Primo, formare le persone, perché senza competenze interne ogni infrastruttura è un monumento inutile. Secondo, validare i casi d'uso in cloud, dove si misura il ritorno prima di comprare una sola GPU. Terzo, scegliere il livello di macchina giusto sul volume reale, senza sovradimensionare per moda. Quarto, portare in locale ciò che è critico, governato da una piattaforma che decide quale modello usare per quale task, e che fa fallback automatico quando una fonte si spegne.
Ma un modello, da solo, non basta
C'è un punto che spesso si dimentica in queste discussioni. Un agente AI è utile quanto i sistemi a cui può accedere. Il modello è il motore, ma senza connessione ai dati e ai processi aziendali resta un oggetto che racconta, non che fa.
È il motivo per cui in AIsuru abbiamo costruito, e continuiamo a far crescere, una collezione di oltre venti connettori MCP, orchestrati da un gateway proprietario che gestisce sicurezza, identità e permessi. Un agente AIsuru, senza scrivere una riga di codice, può leggere e inviare email su Outlook anche con allegati, navigare i documenti SharePoint rispettando i permessi di ogni utente, interrogare in linguaggio naturale CRM come Salesforce e Dynamics 365, leggere database di produzione anche legacy, creare file Word ed Excel veri con formule e carta intestata, innescare workflow su n8n o Zapier, ed eseguire task ricorrenti in autonomia tramite lo Scheduler interno.
Il pezzo che fa la differenza tra una demo e un progetto in produzione, però, è quello che non si vede: il gateway. Ogni connettore passa da un layer proprietario che gestisce login per singolo utente, credenziali e token cifrati, verifica dell'identità a ogni chiamata, isolamento dei dati, log e scadenze automatiche. È la differenza tra l'AI che racconta e l'AI che fa, dentro i confini di sicurezza che un'azienda pretende.
In conclusione
La sovranità tecnologica non significa avere il modello più potente del mondo, perché quello sarà sempre di qualcun altro per qualche mese. Significa non poter essere staccati dalla presa. Significa modelli aperti su hardware nostro, governati da una piattaforma che orchestra, connette, traccia e applica le policy aziendali.
E la cosa più importante è questa: per la prima volta abbiamo, già oggi sul mercato, tutti i pezzi per iniziare. Modelli aperti di buon livello, hardware acquistabile, incentivi fiscali in vigore. Manca solo la decisione di partire.
La mia, come Europa e come Italia, è che vada presa adesso.
Se volete capire cosa potrebbe fare un agente connesso ai vostri sistemi, e su quale infrastruttura, scriveteci. I casi più interessanti nascono sempre da una domanda concreta.
#AI #SovranitaDigitale #AIGovernance #MultiLLM #OnPremise #EnterpriseAI #AIAct #Industria40 #MCP #DeepSeek #Nemotron #AIsuru #Memori